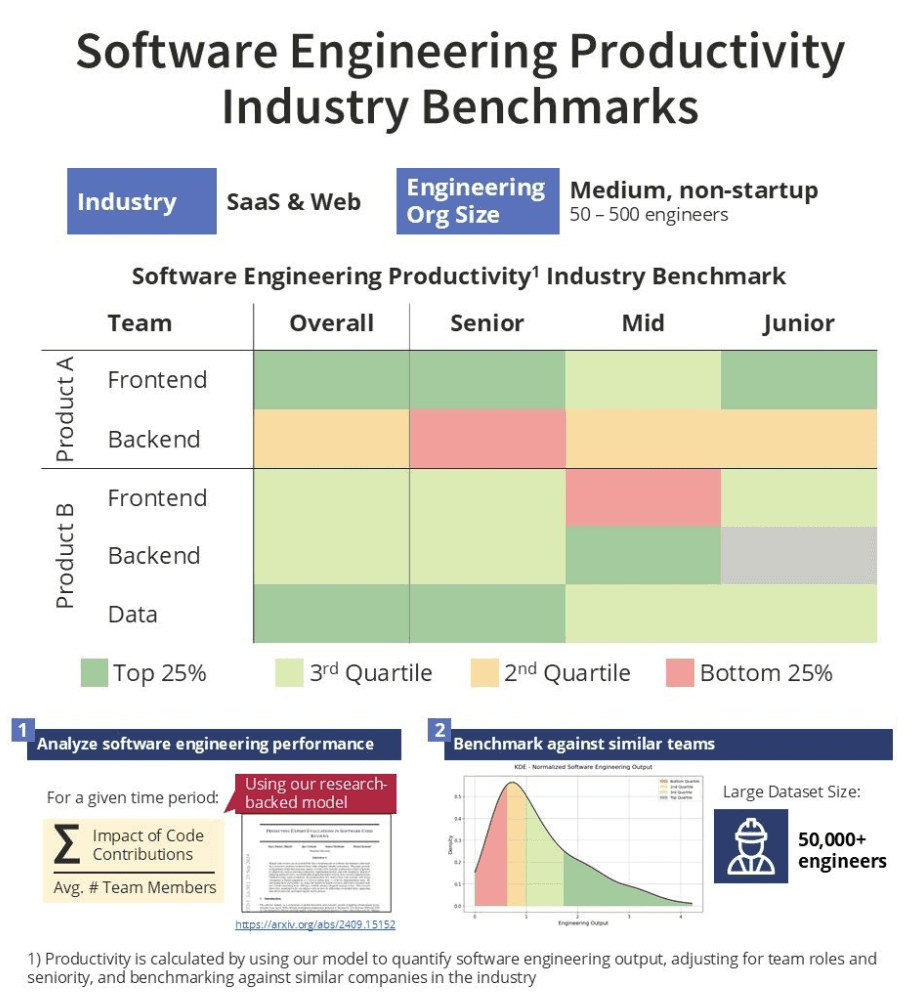
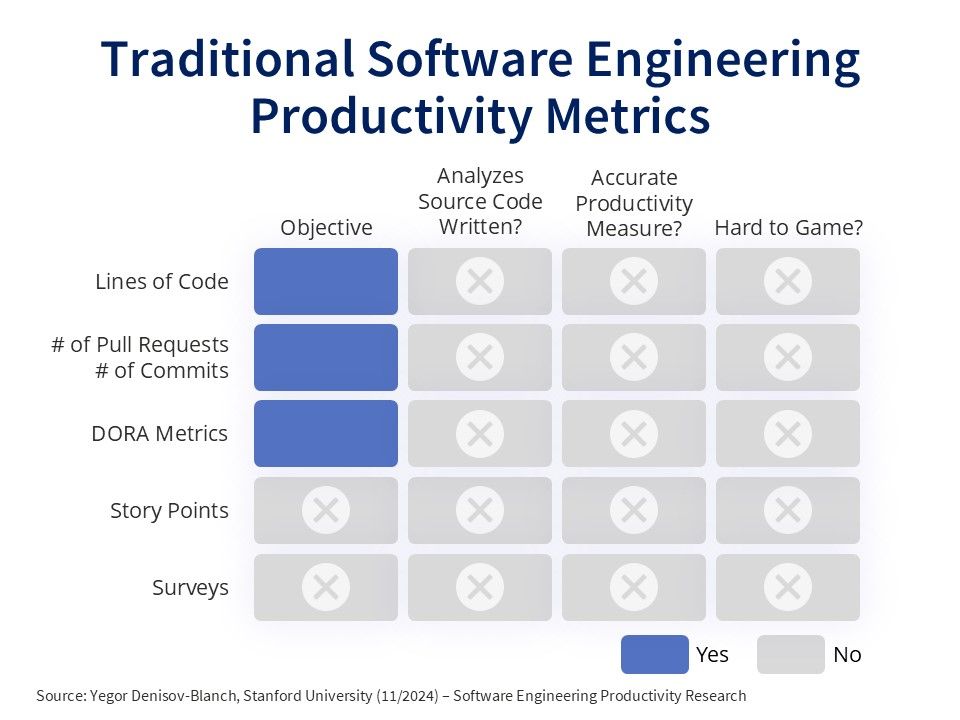
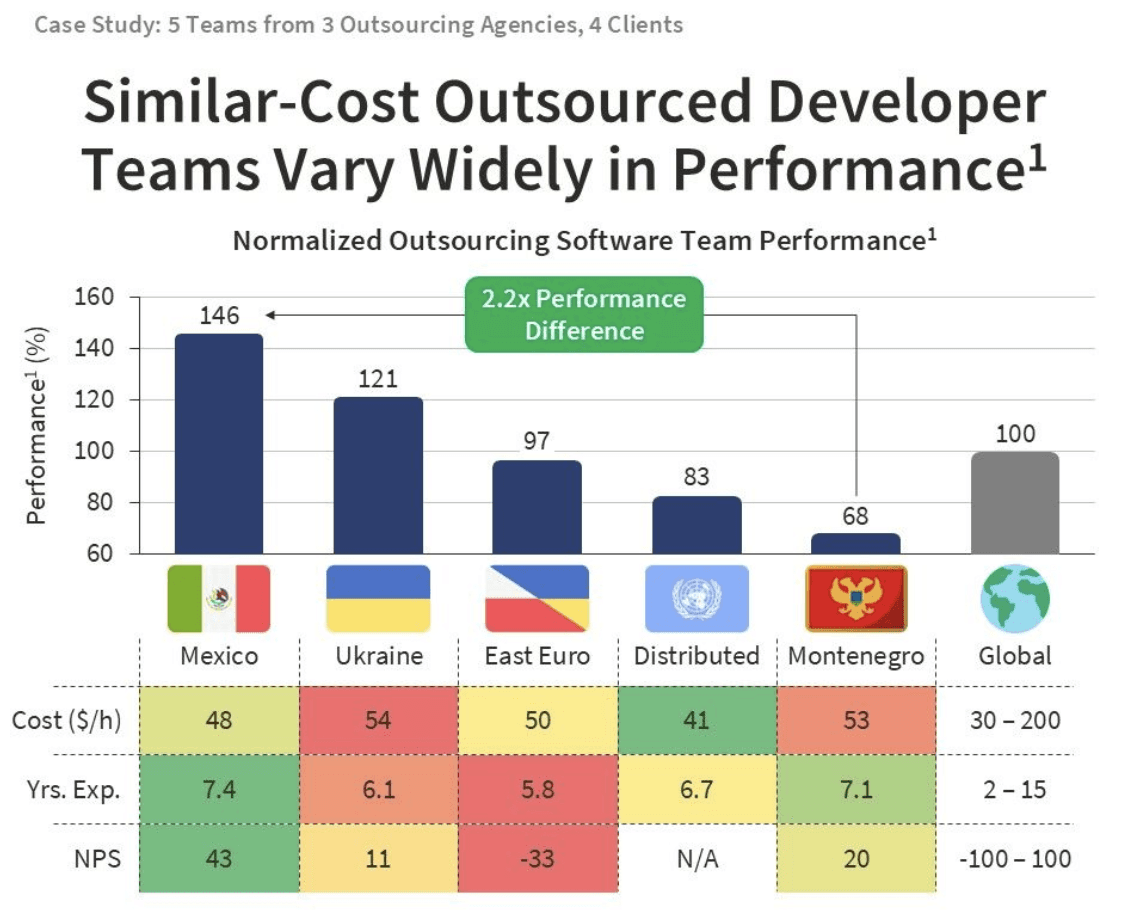
🤔Has Google finally caught up to OpenAI?
Gemini 1.5 Pro has the largest context window of any foundation model. It can handle:
-1 hour of video 🎥
-11 hours of audio 🎧
- 30k+ lines of code 💻
- 700k+ words (1,500 pages of text) 📚
❓ How does Gemini 1.5 Pro perform relative to GPT-4?
Google's research highlights that its latest model surpasses GPT-4 in both large-context and multimodal tasks according to their benchmarks.
The model's ability to solve "needle-in-a-haystack" problems, where it finds specific details within vast amounts of data, is particularly strong.
✅ In tasks requiring the identification of a single piece of information from large datasets (single needle-in-a-haystack), the model achieved an exceptional recall rate of >99.7%.
🔄 When facing more challenging tasks that involve locating multiple pieces of information (multiple needle-in-a-haystack), the model outperformed GPT-4, although it failed to retrieve ~40% of relevant information, limiting its practical application.
🧐 In terms of "Core Capability" (i.e., performance in tasks not requiring extensive context), Google has only compared its model to the earlier Gemini 1.0. This suggests that Gemini 1.5 Pro may not consistently exceed GPT-4's performance yet.
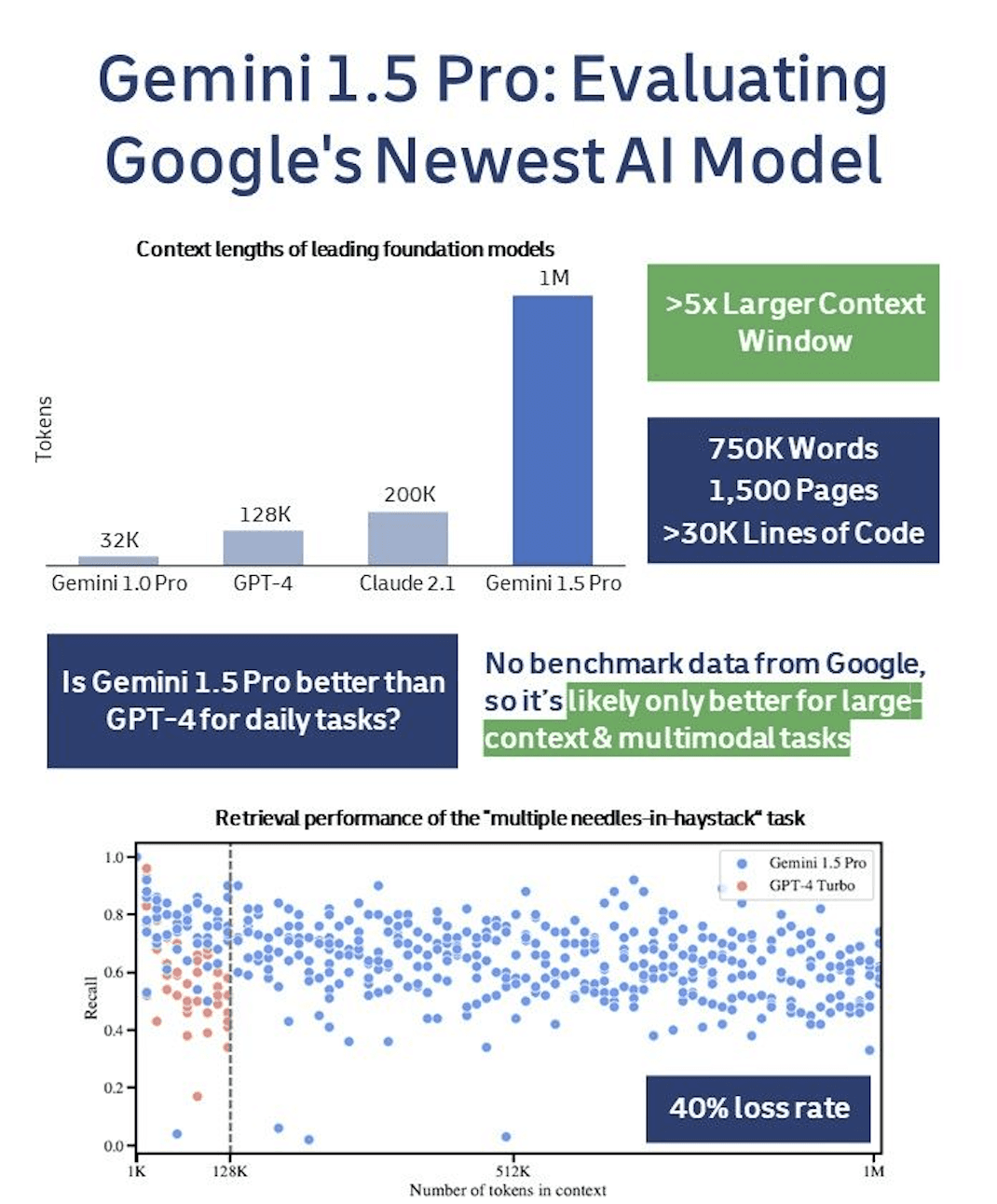
Google seems to be moving in the right direction with this by carving out niches where their models are superior.
It will be interesting to see how Gemini 1.5 Pro stacks up against GPT-4 in user-generated benchmarks.